
İAZAR: Model pentru transcrierea vocii
Iazar

Proiectul dat este elaborat în cadrul competiției Tekwill Junior Ambasadors.
De ce Iazar?
yazar în limba turcă semnifică scriitor,
drept IA + yazar = IAzar, inteligență artificială scriitoare.
Scopul proiectului
Deseori aplicațiile care utilizează transcrierea vocii nu înțeleg anumite graiuri. Aceasta poate fi deranjant mai ales la transcrierea mesajelor vocale, unde vorbitorii tind să vorbească în graiul matern.
Scopul nostru este să antrenăm un model de transcrierea vocii în text, să transcrie graiul matern Moldovenesc.

Alte utilizări
Un astfel de model are mai multe utilități.
Mesajele Vocale
Textul transcris din mesajele vocale poate fi copiat, tradus. Textul fiind în genere mai ușor de utilizat, și mai comod de-l citit. Ăsta v-a fi scopul în jurul căruia vom lucra.
Subtitrări:
Textul transcris dintr-un video poate fi folosit pentru subtitrări.
Jurnalistică:
Jurnaliștii pot să folosească textul transcris din întrevederile lor în articole, care eventual poate fi traduse și în alte limbi. De asemenea textul transcris poate fi folosit pentru subtitrarea întrevederilor.
Persoanele cu dizabilități
Modelul poate fi extins pentru a ajuta persoanele cu dizabilități.
Datele
Date pentru antrenarea în limba română a unui model de transcrierea vocii sunt oferite de către Mozilla
![]()
Explorarea
În set de date găsim:
cv-corpus-15.0-2023-09-08
├── clips
│ ├── common_voice_ro_38436395.mp3
│ ...
├── clip_durations.tsv
├── dev.tsv
├── invalidated.tsv
├── other.tsv
├── reported.tsv
├── test.tsv
├── times.txt
├── train.tsv
└── validated.tsv
Toate fișierele (cu excepția:
reported.tsv,
clip_durations.tsv)
conțin cîte o coloană cu identificatoare, calea spre audio,
transcripția, numărul de aprecieri de la validare, vîrsta, genul, și altele mai puțin importante.
Fișierul validated.tsv conține descrieri despre toate audiourile validate de voluntarii de la common voice, fiind apreciate relativ înalt.
Fișierul invalidated.tsv conține descrieri despre audiouri cu aprecieri negative din partea voluntarilor.
Fișierul train.tsv este folosit pentru antrenarea modelului,
fișierul dev.tsv este folosit pentru validarea modelului, și
fișierul test.tsv este folosit pentru testarea modelului.
Fișierul other.tsv conține descrieri despre audiouri de rezervă.
Fișierele times.txt și clip_durations.tsv descriu durata audiourilor.
În fișierul reported.tsv sunt lista de date care au anumite erori, aceste fu raportate de către voluntari.
Erorile puteau fi utilizarea alfabetelor străine, greșeli de lexic sau pronunție, date pentru limbă străină, etc.
În mapa ./clips/ se află audiourile.
Prelucrarea
Pentru simplitate noi am eliminat toate datele cu erori descrise în reported.tsv.
Am utilizat utilitățile GNU pentru a șterge toate datele defectate.
for i in $(awk -F '\t' '{print $1}' reported.tsv | sed '1d' )
for audio_name in $(grep $i *tsv | awk -F'\t' '{print $2}')
if test -f "./clips/$audio_name"
rm "./clips/$audio_name"
end
sed -i "/$audio_name/d" *.tsv
end
end
-
Prima buclă
forparcurge fiecare valoare din prima coloană a fișieruluireported.tsvutilizînd comandaawk(se utilizează comandasedpentru a exclude prima linie). Aceasta fiind textele datelor cu erori. -
În interiorul primei bucle
for, se deschide o altă buclăforcare parcurge fiecare linie$i, ce conține textul defectat, găsită cu ajutorul comenziigrepdin toate fișierele cu extensiatsvși cu ajutorul comenziiawkse extrage coloana a 2-a, adică denumirea fișierului audio. -
În interiorul celei de a doua bucle, se verifică dacă există fișierul în mapa
./clips/cu numele specificat de variabila $audio_name (denumirea fișierului audio). Dacă există, fișierul respectiv este șters folosind comandarm. -
După ștergerea fișierului, se utilizează comanda
sedpentru a elimina toate liniile care conțin valoarea $audio_name (adică numele fișierului audio defectat) din toate fișierele cu extensiatsv.
Coqui

Pentru a-mi atinge scopurile ințial am ales modelul Coqui Speech To Text.
Avantaje
-
Este un model foarte bine documentat, dotat cu explicații bune și exemple.
-
Are drept logo o broscuță drăguță
-
Poate transforma datele de la common voice în formatul pe care-l necesită.
$ bin/import_cv2.py --filter_alphabet calea/căstre/un/alphabet.txt /calea/către/archivul/common-voice/extras
Aceasta v-a crea cîte un wav fișier din fiecare fișier mp3, și cîte un csv fișier.
Fișierele csv vor conține:
`wav_filename` - calea către fișierul audio. `wav_filesize` - mărimea fișierilor în biți, folosită pentru sortare. `transcript` - transcripția la audio.
Dezavantaje
- Din păcate proiectul nu mai este menținut de dezvoltatori
- Din cauza că proiectul a fost abandonat de dezvoltatori, el necesită dependențe învechite. Din cauza aceasta pot apărea probleme cu setarea modelului
Antrenarea modelului

Pentru antrenarea modelului am folosit Docker
după sfatul a dezvoltatorilor coqui.
Docker este o aplicație folosită pentru a simplifica crearea aplicațiilor, implementarea lor și rularea lor folosind containere.
Care permite dezvoltatorului să împacheteze aplicația împreună cu toate componentele necesare.
Aceasta garantează ca aplicația să poată lucra pe orice sistem nu numai pe a dezvoltatorului.

După ce am setat docker, am instalat modelul cu ajutorul comenzii:
$ docker pull ghcr.io/coqui-ai/stt-train:latest
Această comandă descarcă cîțiva Gb de date. Descărcarea fiind destul de înceată.
Pentru accesarea containerului am utilizat comanda:
$ docker run -it -v ./cv-corpus-15.0-2023-09-08/ro:/cv-data/ ghcr.io/coqui-ai/stt-train:latest
./cv-corpus-15.0-2023-09-08/ro/ fiind fișierul cu date de la common voice,
/cv-data/ este denumire cu care vom putea accesa fișierul de la common voice din container.
Antrenăm inteligența cu următoarea comandă:
$ python -m coqui_stt_training.train\
--train_files /cv-data/clips/train.csv\
--dev_files /cv-data/clips/dev.csv\
--test_files /cv-data/clips/test.csv\
--checkpoint_dir /cv-data/checkpoints_new\
--dropout_rate 0.3\
--scorer /cv-data/scorer/kenlm-romanian.scorer
Pași și epoci
În antrenament, un pas este o actualizare a gradientului; adică o încercare de a găsi cea mai mică sau minimă pierdere. Cantitatea de procesare efectuată într-un singur pas depinde de dimensiunea lotului. În mod implicit, train.py are o dimensiune de lot de 1. Adică, procesează un fișier audio în fiecare pas.
O epocă este un ciclu complet prin datele de antrenament. Adică, dacă aveți 1000 de fișiere listate în fișierul
train.tsv, atunci vă veți aștepta să procesați 1000 de pași pe epocă (presupunând o dimensiune a lotului de 1)
Putem deci simplu afla lungimea unei epoci, enumerînd cu ajutorul comenzii wc numărul de linii
conținute de fișierul de antrenare train.tsv (excluzînd prima linie).
$ wc train.tsv -l
5173 train.tsv
În cazul nostru, folosind diminsiunea loturilor implicită, o epocă v-a avea 5172 de pași.
Experiența
Pe calculator 8Gb RAM, Procesor AMD Rayzen 7 3700u
Experiența … dureroasă
În decurs de aproape o săptămînă, modelul n-a reușit să efectueze nici o epocă
Pe calculator cu 15Gb RAM, procesor AMD Rayzen 5 5000
Rapid de încet
Școala mi-a oferit un calculator pentru antrenarea Inteligenței Artificiale. De acum modelul efectua o epocă în decurs de ~2,5 zile. Este un progres considerabil comparativ cu mediul anterior. Dar oricum este puțin. Conform documentației modelul are nevoie de ~75 de epoci deci reiese ~187.5 zile pentru antrenarea completă a modelului…

Pe calculator 8Gb RAM, procesor Intel i5 10400F, procesor grafic Nvidia 1650
*** Nu antrenați utilizînd numai procesorul. ***
Acest manual presupune că veți folosi GPU-uri NVIDIA. Antrenarea unui model de recunoaștere a vorbirii 🐸STT numai pe CPU va dura foarte, foarte, foarte mult timp. Nu antrenați cu procesorul.

Acum suntem convinși faptul că pentru antrenarea modelului pe un calculator lipsit
de cartelă NVIDIA îmi va lua foarte mult timp.

Avînd din păcate numai 4 rinichi la dispoziție nu suntem în stare să cumpărăm Nvidia. Din bucurie a fost găsit un voluntar care ne permise să utilizăm computătorul său cu o placă grafică NVIDIA, astfel prevenind sacrificiul de rinichi pentru buna cauză.
Am urmărit documentația Coqui pentru setarea mediului de antrenare. Din păcate, în pofida celor mai bune intenții ale prietenului nostru, a orelor investite în setarea mediului, n-am reușit să setăm mediul de antrenare pe Windows prin wsl(subsistema windows pentru linux).
Colab

Cu toate că coqui oferă caiete jupyter,
lipsa de support din partea dezvoltatorilor ne-a ajuns însă și aici.
Problema dependențelor în cazul dat fiind cea mai evidențiată.
Spre exemplu versiunea de TenserFlow
necesitată de coqui nu mai era disponibilă în pypi.
Recunoaștere…
Curiozitatea și neștiința m-a făcut să ignor orice semne și orice sfaturi.
Chiar coqui recomanda alternative.
A venit timpul să nu le mai ignorăm, și să încercăm norocul pentru a-mi atinge scopurile…
Whisper

Whisper este un model pentru transcrierea vocii dezvoltat de OpenAI.
Avantaje
- Are o comunitate mare
- Este mereu dezvoltat și actualizat
Dezavantaje
- N-are drept logo o broscuță drăguță
Colectarea datelor
Modelul se va antrena cu ajutorul datelor în format csv, similar structurii utilizate anterior
. Pentru simplitate vom utiliza serviciile oferite de HuggingFace
pentru gestionarea datelor de antrenare.

Am decis să colectăm date de la voluntari(colegi/prieteni). Ca să le fie mai simplu voluntarilor să doneze date am creat un strîngător de date.
Strîngătorul reprezintă un bot telegram cărui îi transmiți un mesaje vocale și transcrierea lor.
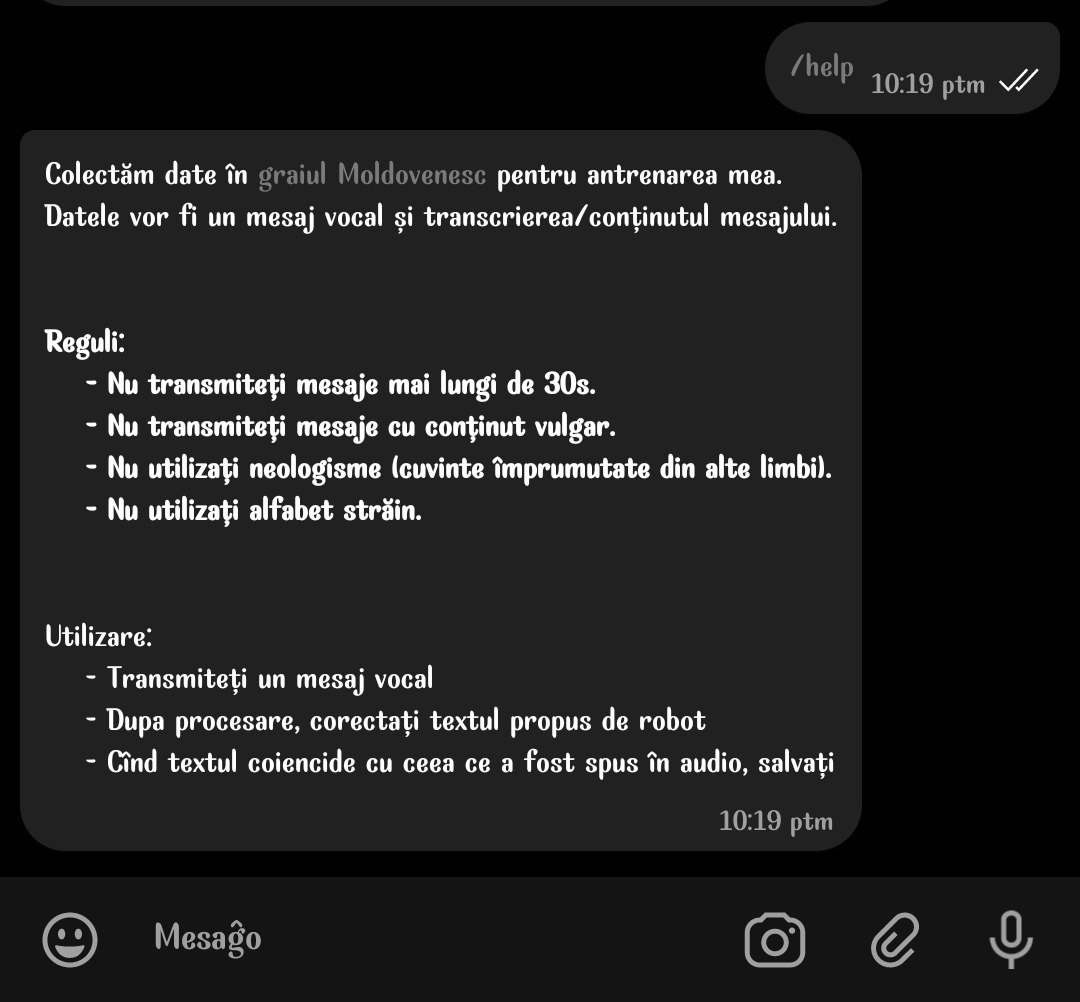
Dupa o scurtă perioadă de timp am strîns aproximativ 50 de date audio. Am considerat că este destul pentru o mică adjustare.
Datele colectate au fost plasate pe un depozit de pe HuggingFace. Din frica ca să nu fie datele colectate utilizate împotriva voluntarilor, am decis să facem depozitul privat.
Common Voice 
 Pentru rezultate mai bune am folosit și date de la Mozilla Common
Voice. Anume datele de pe
repozitoriul HuggingFace Common Voice
11_0.
Pentru rezultate mai bune am folosit și date de la Mozilla Common
Voice. Anume datele de pe
repozitoriul HuggingFace Common Voice
11_0.
Codul

Modelul a fost antrenat pe o versiune gratisă de GoogleColab.
Noi am modificat caietul lui Sanchi Gandhi
pentru a satisface necesitățile noastre.
Cele mai notabile modificări fiind:
- Am schimbat bazele de date.
Inițial am antrenat modelul pe bazele de date de la Common Voice, apoi am
antrenate pe datele noastre.
-
Am schimbat limba, exemplul inițial fiind pentru limba Hindu.
-
Am conectat colabul la
depozitul nostru HuggingFace -
Am tradus documentația
Caietul final -> https://nbviewer.org/github/Yehoward/IAZAR/blob/master/code_de_antrenare_iazar.ipynb
Rezultate

Am testat mai multe modele pe un audio înregistrat de către Crinela.
Textul așteptat:
Mâine este paștele, toți au pregătit păscuțele pentru sfințit.
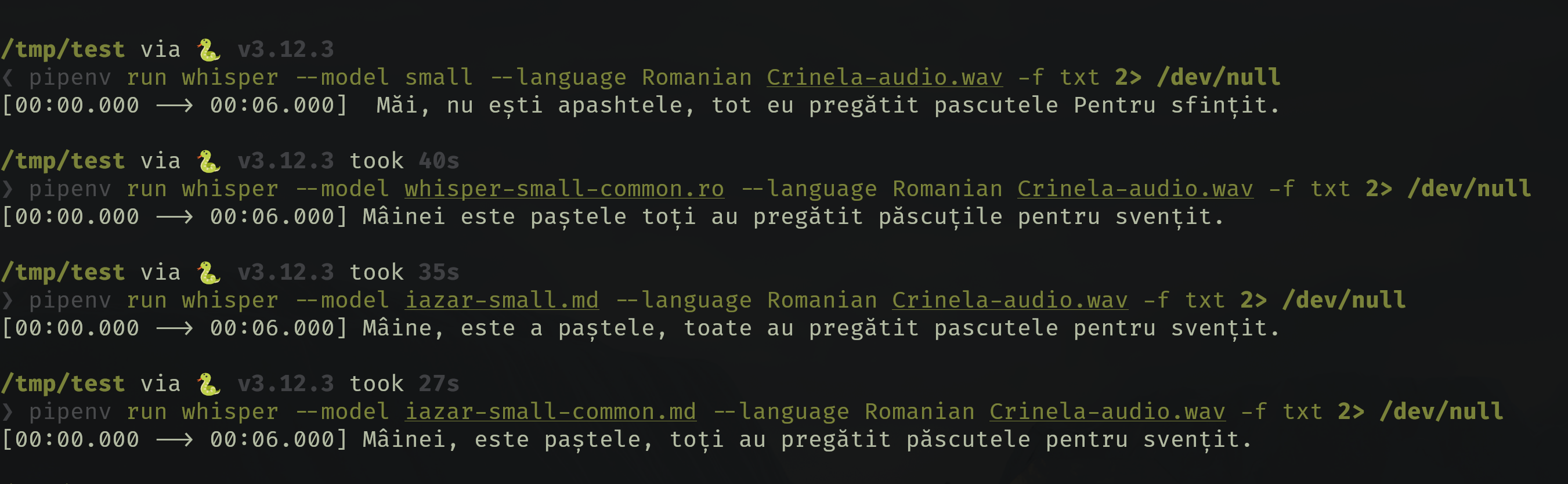
- Primul îi modelul inițial whisper
- Al doilea îi antrenat numai cu date de la mozilla
- Al treilea îi antrenat numai cu datele noastre
- Al ultimulea îi antrenat atît cu datele noastre cît și cu cele de la mozila
După cum observăm toate modelel adjustate de noi au performanță mai bună decît
modelul inițial de la Whisper. Din punctul nostru de vedere, din toate
modelele cea mai bună performanță a avut-o cea antrenată pe datele noaste și
cele de la Common Voice.
Metode de implementare a modelului
Bot pentru telegram
Am făcut un bot telegram, care poate transcrie înregistrări vocale, fișiere audio, video pînă la 20Mb (din cauza limitărilor de la telegram).
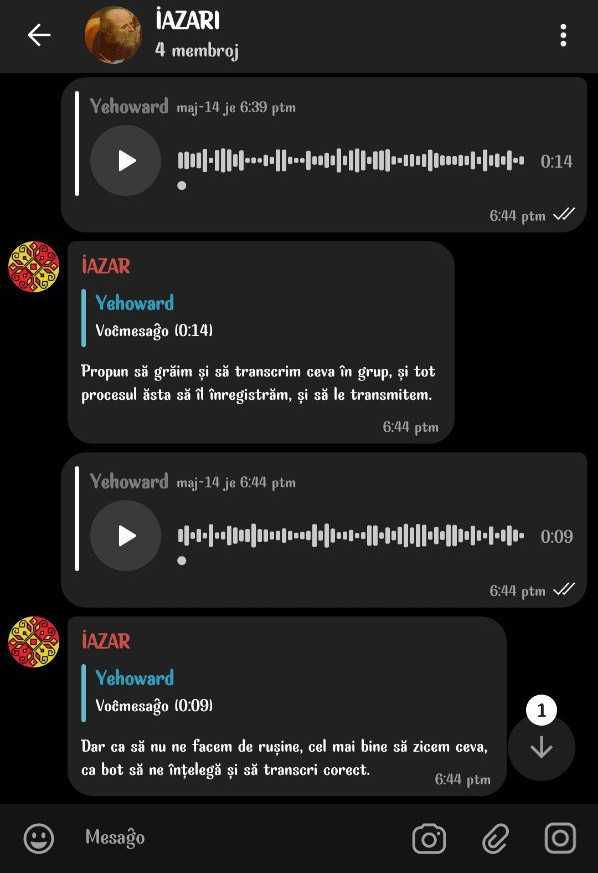
Botul la bază folosește librăria transformers,
care permite să lucrezi mai ușor cu modele încărcate direct pe HuggingFace.
Membrii Echipei

Copiist

Conducătoare

Fața proiectului
Concluzie


Decernarea cîștigătorilor vedeți aici -> premierea


{kind=link}